Frequently Asked Questions¶
See our documentation homepage for information about our most common topics.
- I have a new phone. How do I move my Duo onto it?
- How do I acknowledge use of CURC Resources?
- How do I check how full my directories are?
- When will my job start?
- How can I get system metrics?
- How much memory did my job use?
- Where is my current fair share priority level at?
- Why is my job pending with reason ‘ReqNodeNotAvail’?
- Why do I get the following ‘Invalid Partition’ error when I run my job?:
sbatch: error: Batch job submission failed: Invalid partition name specified. - Why do I get the following ‘Invalid Partition’ error when I run a Blanca job?
- How can I check what allocations I belong to?
Why do I get the following ‘LMOD’ error when I try to load a slurm module?:
Lmod has detected the following error: The following module(s) are unknown: "slurm/alpine" - How do I install my own python library?
- Why does my PetaLibrary allocation report less storage than I requested?
I have a new phone. How do I move my Duo onto it?¶
You can add a new device to your duo account by visiting https://duo.colorado.edu. After a CU authorization page you will be directed to a Duo authentication page. Ignore the Duo Push prompt and instead click “Add a new device”:
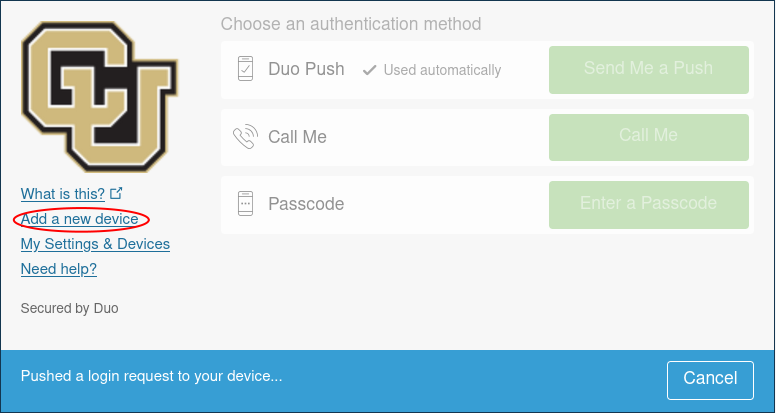
Duo will then try to authenticate your account by push notification to verify your identity. Cancel this push notifcation…
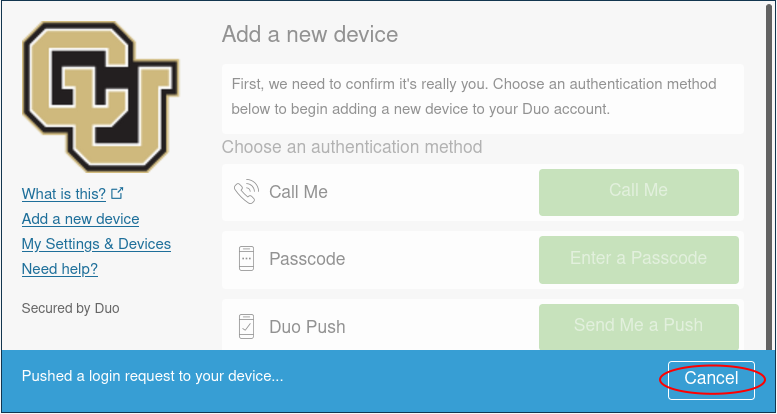
…and click on “Enter a Passcode”, or “Call Me”.
- If you select “Call Me” the simply recieve the call and press 1.
- If you select “Enter a passcode” then click “Text me new codes” and you will be sent a list of one time passwords. Type in any one of the codes and you will be authenticated.
Once you have verified your identity, follow the instructions provided by Duo to add your device.
If you cannot authenticate your account (e.g. do not have your old device), contact rc-help@colorado.edu for further assistance.
How do I check how full my directories are?¶
You have three directories allocated to your username ($USER). These include /home/$USER (2 G), /projects/$USER (250 G) and /scratch/alpine/$USER (10 T). To see how much space you’ve used in each, from a login node, type curc-quota as follows:
[janedoe@login11 ~]$ curc-quota
------------------------------------------------------------------------
Used Avail Quota Limit
------------------------------------------------------------------------
/home/janedoe 1.7G 339M 2.0G
/projects/janedoe 67G 184G 250G
/scratch/alpine1 1050G 8950G 10000G
You can also check the amount of space being used by any directory with the du -sh command or the directory’s contents with the du -h command:
[janedoe@c3cpu-a7-u26-3 ~]$ du -h /scratch/alpine/janedoe/WRF
698M WRF/run
698M WRF
When will my job start?¶
You can pull up information on your job’s start time using the squeue command:
squeue --user=your_rc-username --start
Note that Slurm’s estimated start time can be a bit inaccurate. This is because Slurm calculates this estimation off the jobs that are currently running or queued in the system. Any job that is added in later with a higher priority may delay your job.
For more information on the squeue command, take a look at our Useful Slurm Commands tutorial. Or visit the Slurm page on squeue
Note that you can also see system level wait times and how they change through time by visiting the CURC metrics portal at https://xdmod.rc.colorado.edu
How can I get metics about CURC systems such as how busy they are, wait times, and account usage?¶
Visit the CURC metrics portal at https://xdmod.rc.colorado.edu
How much memory did my job use?¶
You can check how much memory your job used by using the sacct command. Simply replace YYYY-MM-DD with the date you ran the job:
sacct --starttime=YYYY-MM-DD --jobs=your_job-id --format=User,JobName,JobId,MaxRSS
If you’d like to monitor memory usage on jobs that are currently running, use the sstat command:
sstat --jobs=your_job-id --format=User,JobName,JobId,MaxRSS
For more information on sstat or sacct commands, take a look at our Useful Slurm Commands tutorial. Or visit the Slurm reference pages on sstat and sacct.
You can also view information related to service unit (SU) usage and CPU & RAM efficiency by using slurmtools. Note that CPU & RAM efficiency statistics will be included in emails sent when a job completes, if requested.
Why is my job pending with reason ‘ReqNodeNotAvail’?¶
The ‘ReqNodeNotAvail’ message usually means that your node has been reserved for maintenance during the period you have requested within your job script. This message often occurs in the days leading up to our regularly scheduled maintenance, which is performed the first Wednesday of every month. So, for example, if you run a job with a 72 hour wall clock request on the first Monday of the month, you will receive the ‘ReqNodeNotAvail’ error because the node is reserved for maintenance within that 72-hour window. You can confirm whether the requested node has a reservation by typing scontrol show reservation to list all active reservations.
If you receive this message, the following solutions are available:
- Run a shorter job that does not intersect the maintenance window
You can update your current job’s time so that it does not intersect with the maintenance window using the
scontrolcommand:$ scontrol update jobid=<jobid> time=<time>
- Wait until after maintenance window has finished, your job will resume automatically
Why do I get an ‘Invalid Partition’ error when I try to run a job?¶
This error usually means users do not have an allocation that would provide the service units (SUs) required to run a job. This can occur if a user has no valid allocation, specifies an invalid allocation, or specifies an invalid partition. Think of SUs as “HPC currency”: you need an allocation of SUs to use the system. Allocations are free. New CU users should automatically get added to a ‘ucb-general’ allocation upon account creation which will provide a modest allocation of SUs for running small jobs and testing/benchmarking codes. However, if this allocation expires and you do not have a new one you will see this error. ‘ucb-general’ allocations are intended for benchmarking and testing and it is expected that users will move to a project allocation. To request a Project and apply for a Project Allocation visit our allocation site.
Why do I get an ‘Invalid Partition’ error when I try to run a Blanca job?¶
If you are getting an ‘invalid patition’ error on a Blanca job which you know you have access to or have had access to before, you may be in the slurm/alpine scheduler instance. From a login node, run module load slurm/blanca to access the Slurm job scheduler instance for Blanca, then try to resubmit your job.
How can I check what allocations I belong to?¶
You can check the allocations you belong to with the sacctmgr command. Simply type:
sacctmgr -p show associations user=$USER
…from a login or compile node. This will print out an assortment of information including allocations and QoS available to you. For more information on sacctmgr, check out the Slurm’s documentation
Why do I get an ‘LMOD’ error when I try to load Slurm?¶
The slurm/alpine module environment cannot be loaded from compile or compute nodes. It should only be loaded from login nodes when attempting to switch between Blanca and Alpine enviornments. This error can be disregarded, as no harm is done.
How do I install my own python library?¶
Although Research Computing provides commonly used Python libraries as module, you may need to install individual python libraries for your research. This is best handled by utilizing Research Computing’s Anaconda installation to set up a local Conda enviornment.
Why does my allocation report less storage than I requested?¶
Every ZFS-based PetaLibrary allocation has snapshots enabled by default. ZFS snapshots are read-only representations of a ZFS filesystem at the time the snapshot is taken. Read more about ZFS Snapshots
PetaLibrary allocation sizes are set with quotas, and ZFS snapshot use does count against your quota. Removing a file from your filesystem will only return free space to your filesystem if no snapshots reference the file. Filesystem free space does not increase until a file on a filesystem and all snapshots referencing said file are removed. Because snapshots can cause confusion about how space is utilized within an allocation, the default snapshot schedule discards snapshots that are more than one week old.
If you would like to set a custom snapshot schedule for your allocation, please contact rc-help@colorado.edu. Note that the longer you retain snapshots, the longer it will take to free up space by deleting files from your allocation.
Why is my Jupyter session pending throwing ‘QOSMaxSubmitJobPerUserLimit’?¶
Some of our Open OnDemand applications allocate resources, which can be limited to one session. All Open OnDemand applications that submit jobs to Alpine’s ahub partition have this limitation. Currently, all applications with “Presets” in their name will be submitted to the ahub partition. This partition provides users with rapid start times, but limits users to one Jupyter session (or any one job using the partition). In order to spawn another Jupyter session, you first need to close the current job. You can do so by shutting down your current Jupyter session or by canceling your job manually.